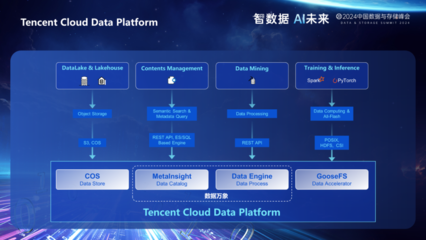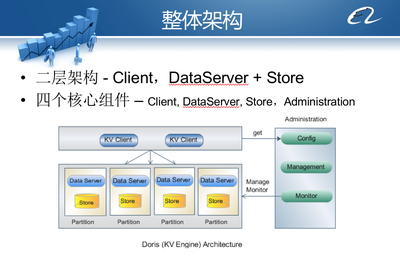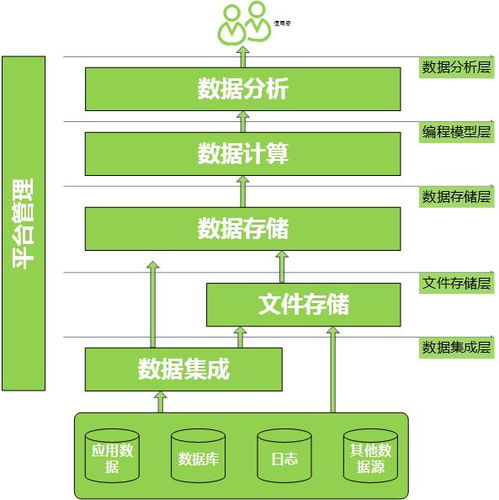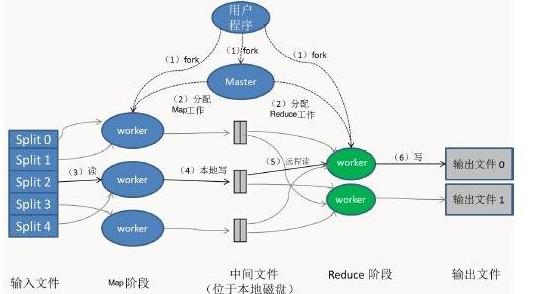
在科研工作中,数据可视化是呈现研究成果、揭示科学规律的关键环节。实验或模拟过程中产生的原始数据图,常因格式不兼容、分辨率过低、坐标标注模糊、色彩对比度差或图像压缩失真等原因而变得难以辨识或直接使用。这不仅影响论文、报告的美观与专业性,更可能掩盖重要数据特征,导致信息误读。针对科研数据处理中的这一常见痛点——模糊数据图的重新绘图,已成为提升数据呈现质量与科研交流效率的核心需求。本文将探讨其重要性、技术路径,并阐述专业信息技术咨询服务在此过程中的支撑作用。
一、 模糊数据图重新绘图的重要性与挑战
- 确保数据准确传达: 清晰的图表能精确展示数据点、趋势线、误差范围及统计显著性,避免因图像模糊造成的解读歧义,保障科学结论的可靠性。
- 符合出版规范: 高水平期刊对插图的分辨率、字体、线宽、色彩模式(如CMYK)等有严格规定。重新绘制模糊原图,是满足投稿要求的必要步骤。
- 提升视觉表现力: 通过专业的图形软件重新设计,可以优化布局、增强关键数据的视觉突出性、采用更科学的配色方案,使研究成果更具说服力和影响力。
- 主要挑战: 挑战在于如何从低质量图像中准确提取原始数据点,以及选择并熟练运用合适的工具,高效、精准地完成重建。对于复杂图表(如三维曲面、多轴图),技术门槛较高。
二、 重新绘图的核心技术路径与方法
- 数据提取与重建:
- 手动数字化: 对于简单图表,可使用GetData Graph Digitizer、Engauge Digitizer等软件,通过手动选点的方式从图像中提取坐标数据。
- 自动化工具: 部分高级图像处理算法或专用软件可尝试自动识别图表中的曲线与数据点,但通常需人工校验和修正。
- 追溯原始数据: 最理想且准确的方法是找到生成该图表的原始数据文件(如.csv, .txt, .mat等),直接从源头进行重新绘图。
- 专业绘图软件的应用:
- 科学与工程绘图: OriginLab, MATLAB, Python(Matplotlib, Seaborn库), R(ggplot2包)等,功能强大,定制化程度高,适合生成出版级图表。
- 通用图表与矢量图: Microsoft Excel(高级图表功能), PowerPoint, Adobe Illustrator, Inkscape等,适用于制作演示文稿或进行细致的矢量图形编辑与美化。
- 流程选择: 通常先在科学软件中生成精确的图表框架并导出为矢量格式(如EPS, PDF),再在Illustrator等软件中进行最后的排版、标注与美化。
- 绘图原则与最佳实践:
- 清晰性与一致性: 确保坐标轴标签、单位、图例清晰无误,全文图表风格统一。
- 信息最大化与简化: 在有限空间内有效展示核心信息,去除不必要的装饰元素(“图表垃圾”)。
- 色彩与可访问性: 考虑色盲友好配色,并确保灰度打印时仍能区分不同数据系列。
三、 信息技术咨询服务的价值体现
面对繁重的科研任务与技术工具的学习曲线,许多研究团队选择寻求专业的信息技术咨询服务,以获得高效、高质量的解决方案。此类服务在模糊数据图重新绘图方面可提供:
- 技术方案咨询与定制: 根据图表类型、复杂度和最终用途(期刊投稿、项目结题、学术海报等),顾问会推荐最优的软件组合与技术流程,制定个性化的重绘方案。
- 数据提取与处理支持: 协助使用专业工具从模糊图像中高保真地提取数据,或帮助整理、清洗和格式化已有的原始数据,为绘图做好准备。
- 绘图实现与优化: 由具备科研背景的技术专家直接操作专业软件,快速、准确地完成图表重绘,确保其科学严谨且视觉美观,完全符合目标要求。
- 技能培训与知识转移: 提供针对特定绘图软件(如Origin, Python Matplotlib)的实操培训,使科研人员掌握核心技能,实现长期自主处理能力。
- 效率与质量保障: 将科研人员从耗时的技术细节中解放出来,使其更专注于核心研究;专业服务能避免因技术不熟导致的错误,提升整体成果质量。
模糊数据图的重新绘图,远非简单的“美化”,而是一项涉及数据准确性、科学规范性与视觉传播效力的关键技术处理环节。它连接着原始科研数据与最终的知识呈现。借助成熟的技术路径与专业的信息技术咨询服务,科研团队能够有效克服这一障碍,确保其数据故事得以清晰、有力、规范地讲述,从而在激烈的学术交流与竞争中,最大化研究成果的价值与影响力。